Trong phần khách mời đặc biệt này, Itamar Ben Hemo, Giám đốc điều hành của Rivery, thảo luận về những điểm chung và khác biệt giữa DevOps vs DataOps. Rivery là một nền tảng DataOps hợp lý hóa việc tích hợp, chuyển đổi và điều phối dữ liệu. Là một nhà điều hành kinh doanh dày dạn kinh nghiệm, Ben là đồng sáng lập và Giám đốc điều hành của Vision.BI, một công ty tư vấn dữ liệu hàng đầu được mua lại bởi Tập đoàn Keyrus. Tại Keyrus, ông là người sáng lập và là phó chủ tịch tập đoàn ở Bắc Mỹ.
Sự khác biệt của DevOps vs DataOps
Nhiều người cho rằng có thể hiểu được rằng DataOps chỉ đơn giản là “DevOps cho dữ liệu”. Mặc dù hai framework có tên giống nhau, nhưng DevOps và DataOps không giống nhau về phương pháp luận. Tuy nhiên, hai khuôn khổ chia sẻ nhiều nguyên tắc chung. Đó là lý do tại sao, đối với các chuyên gia dữ liệu và các bên liên quan khác, điều quan trọng là phải hiểu điều gì khác biệt giữa DataOps và DevOps. Đọc so sánh bên dưới để tìm hiểu mọi thứ bạn cần biết về DevOps so với DataOps.
DevOps tăng tốc độ phân phối các sản phẩm phần mềm chất lượng cao
DevOps kết hợp phát triển phần mềm (Dev) và hoạt động CNTT (Ops) để tăng tốc độ cung cấp các sản phẩm phần mềm chất lượng cao. Bắt nguồn từ cuối những năm 2000, DataOps và DevOps được thiết kế để phá vỡ các hầm chứa nội bộ công ty cắt đứt giao tiếp và phối hợp giữa các nhà phát triển và nhóm CNTT. Sự thiếu gắn kết giữa nhà phát triển và CNTT đã làm căng thẳng việc triển khai phần mềm và dẫn đến các sản phẩm phần mềm bị trì hoãn, kém hiệu quả hoặc bị hỏng.
Bằng cách tập hợp hai bộ phận này dưới một cái ô, các nhóm devops vs dataops có thể viết (nhà phát triển) và triển khai phần mềm (CNTT) trong một khuôn khổ thống nhất, tự động. DevOps đã giới thiệu một tập hợp các phương pháp cốt lõi hiện đã trở thành tiêu chuẩn trong ngành công nghiệp phần mềm, bao gồm:
Quản lý mã nguồn hoặc kiểm soát phiên bản, cho phép các nhóm nhà phát triển theo dõi và kiểm soát các thay đổi trong mã nguồn, trên các phiên bản và khoảng thời gian khác nhau. Tích hợp liên tục (CI) tích hợp mã nguồn của nhà phát triển với một nhánh mã dòng chính, tốt nhất là nhiều lần trong ngày. Kiểm thử tự động thực hiện kiểm tra tự động trên mã nguồn mới để cung cấp cho nhóm phát triển phản hồi ngay lập tức.
Phân phối liên tục (CD) kiểm tra mã mới như một tạo tác phần mềm trong môi trường dàn dựng để đảm bảo chất lượng và tính nhất quán của sản phẩm trước khi đưa vào hoạt động. Triển khai liên tục (cũng là CD) tự động đẩy mã mới trực tiếp vào môi trường sản xuất, lý tưởng là trong khoảng thời gian nhỏ, thường xuyên.
Ngoài các thành phần chính này, các khung công tác devops vs dataops cũng thường xuyên kết hợp phát triển nhanh. Phát triển Agile tập trung vào các bản cập nhật sản phẩm nhỏ, gia tăng thay vì phát hành tất cả cùng một lúc. Agile chia quá trình phát triển phần mềm thành “nước rút”, mỗi bước đều có các mục tiêu được nhắm mục tiêu để nhóm phát triển hoàn thành. Kéo dài 1-4 tuần, chạy nước rút kết hợp phản hồi liên tục của các bên liên quan.
Kể từ khi ra đời cách đây hơn mười năm, DevOps đã nhanh chóng cách mạng hóa cách phần mềm được xây dựng và khởi chạy. Các nhóm DevOps hàng đầu hiện triển khai các bản cập nhật phần mềm thường xuyên hơn 208 lần so với các nhóm nhà phát triển mô hình cũ và duy trì tỷ lệ thất bại thấp hơn 7 lần. DevOps cho phép Amazon triển khai mã mới sau mỗi 11,7 giây và Etsy khởi chạy cập nhật mã hơn 60 lần mỗi ngày.
Với một hồ sơ thành công như vậy, devops vs dataops có vẻ đã chín muồi để ứng dụng vào các lĩnh vực công nghệ khác. Và đó là cách DataOps xuất hiện lần đầu tiên. Nhưng DataOps không chỉ là DevOps cho dữ liệu.
DataOps tự động hóa việc điều phối dữ liệu để nhanh chóng phân phối dữ liệu trên toàn tổ chức
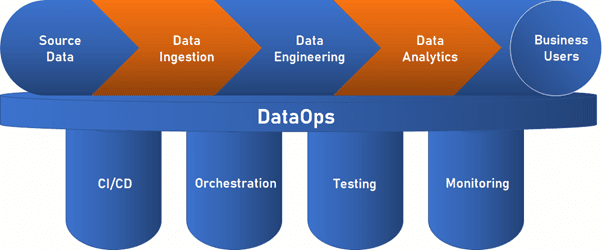
DataOps là một phương pháp kết hợp công nghệ, quy trình, nguyên tắc và nhân sự để tự động hóa việc điều phối dữ liệu trong toàn bộ tổ chức. Các tổ chức sử dụng DataOps và DevOps để cung cấp dữ liệu theo yêu cầu, chất lượng cao cho khách hàng tổ chức bằng cách tăng tốc độ phát triển và triển khai quy trình làm việc dữ liệu tự động.
Khi các tổ chức phát triển và nhu cầu dữ liệu trở nên phức tạp hơn, DataOps cung cấp một khuôn khổ linh hoạt để cung cấp dữ liệu phù hợp, vào đúng thời điểm, cho đúng bên liên quan. DataOps nhanh chóng triển khai cơ sở hạ tầng dữ liệu mới để đáp ứng các ưu tiên thay đổi nhanh chóng của tất cả khách hàng, từ giám đốc điều hành, nhà tiếp thị, đến các SDR.
DataOps áp dụng nhiều nguyên tắc giống như devops vs dataops. Nhưng trong khi DevOps tự động hóa việc triển khai phần mềm, thì DataOps tự động hóa việc điều phối dữ liệu – việc phân phối dữ liệu từ đầu đến cuối từ nguồn đến đích. DevOps xây dựng các sản phẩm phần mềm; DataOps xây dựng quy trình làm việc dữ liệu.
Các luồng công việc dữ liệu này tự động hóa việc nhập, chuyển đổi và điều phối dữ liệu. DataOps sử dụng cơ sở hạ tầng dữ liệu, chẳng hạn như đường ống dữ liệu và các phép biến đổi dựa trên SQL, để cung cấp năng lượng cho các quy trình làm việc tự động này.
“Sản phẩm phần mềm” mà nhóm DataOps làm việc trong quá trình chạy nước rút thường là cơ sở hạ tầng dữ liệu. Trong một số trường hợp, cơ sở hạ tầng thực sự được coi là mã hoặc cơ sở hạ tầng là mã (IaC).
Trong khuôn khổ này, các nhóm DataOps có thể áp dụng các nguyên tắc của DevOps cho IaC như thể nó là bất kỳ sản phẩm phần mềm nào khác. Tuy nhiên, các nhóm khác thích xây dựng cơ sở hạ tầng dữ liệu thông qua nền tảng quản lý dữ liệu và giao diện người dùng, nhưng vẫn áp dụng các nguyên tắc của DevOps trong quá trình xây dựng.
Một số thành phần cốt lõi của DevOps, được liệt kê trong phần trên, áp dụng cho DataOps
Kiểm soát phiên bản cho phép nhóm nhà phát triển theo dõi và kiểm soát devops vs dataops các thay đổi trong cơ sở hạ tầng dữ liệu, trên các phiên bản và khoảng thời gian khác nhau. Điều này hợp lý hóa việc sửa đổi, đảo ngược và gỡ lỗi IaC. Tích hợp liên tục (CI) tích hợp IaC của nhà phát triển với một nhánh mã dòng chính, tốt nhất là vài lần một ngày. Với CI, các nhà phát triển không bao giờ đi chệch quá xa nhánh mã chính.
Kiểm thử tự động thực hiện các kiểm tra tự động trên cơ sở hạ tầng dữ liệu mới để cung cấp cho nhóm phát triển phản hồi ngay lập tức, bao gồm kiểm tra đơn vị, kiểm tra chức năng và kiểm tra đầu cuối. Phân phối liên tục (CD) kiểm tra cơ sở hạ tầng dữ liệu mới trong môi trường dàn dựng để đảm bảo chất lượng và tính nhất quán trước khi đi vào hoạt động. Điều này giúp tránh lỗi và gián đoạn cho người dùng.
Triển khai liên tục (cũng là CD) tự động đẩy cơ sở hạ tầng dữ liệu mới trực tiếp vào môi trường sản xuất, lý tưởng là trong những thay đổi nhỏ, thường xuyên. Thao tác này sẽ loại bỏ các tác vụ hợp nhất mã và đường ống thủ công cũng như tăng tốc cập nhật sản phẩm.
DataOps và DevOps có thể chia sẻ các nguyên tắc phát triển và triển khai giống nhau. Nhưng DevOps chỉ là một thành phần của DataOps. Nhân sự, công nghệ và quy trình nhanh cũng đóng vai trò quan trọng trong DataOps.
Các tổ chức chỉ có thể nhận ra lợi ích đầy đủ của DataOps và DevOps khi tất cả các thành phần này được kết hợp thành một khuôn khổ thống nhất. Mặc dù hai phương pháp này trùng nhau và có tên rất giống nhau, nhưng chúng không thể hoán đổi cho nhau. Nhóm dữ liệu phải hiểu sự khác biệt giữa chúng để xây dựng các khuôn khổ DataOps hiệu quả.
DataOps Khai thác những gì tốt nhất của DataOps và DevOps, nhưng chúng không giống nhau
Khi nền kinh tế trở nên dựa vào dữ liệu nhiều hơn và nhu cầu dữ liệu của khách hàng tổ chức nhanh chóng tăng lên, các nhóm dữ liệu không thể chỉ dựa vào công nghệ để duy trì tính cạnh tranh. Họ phải xây dựng các khuôn khổ tổ chức, nhanh nhẹn để cung cấp dữ liệu khi nào và cách thức các bên liên quan yêu cầu.
Đây là những gì DataOps và DevOps được thiết kế để làm. Bằng cách khai thác devops vs dataops đưa các phương pháp và thực tiễn phát triển phần mềm hàng đầu vào quy trình điều phối dữ liệu, cho phép cung cấp dữ liệu nhanh chóng cho tất cả các khách hàng là tổ chức.
Nếu có một điểm mấu chốt trong bài viết này, thì đó là: DataOps cần các nguyên tắc của DevOps để cung cấp cho các bên liên quan dữ liệu một cách nhanh chóng và hiệu quả, nhưng DevOps và DataOps không giống nhau.
Từ khóa:
- devops vs dataops vs mlops
- devops vs data engineer
- dataops vs devops salary
- data devops tools
- dataops salary
- devops for data engineering
- devops data pipeline
- big data vs devops
Nội dung liên quan:
- Các loại tiền điện tử hàng đầu nên đầu tư vào tháng 9
- Cách quản lý kênh youtube: Mẹo và công cụ
- Cách quản lý người theo dõi trên Instagram một cách hiệu quả và hiệu quả
