Trong vài năm gần đây, một khái niệm mới trong Kiến trúc dữ liệu đã xuất hiện. Nó được gọi là “data lakehouse”. Data lakehouse cung cấp một mô hình mới lấy các đặc điểm tốt nhất của kho dữ liệu (một lượng nhỏ dữ liệu phối hợp) và dữ liệu hồ (một lượng lớn dữ liệu không được phối hợp) và hợp nhất chúng, cung cấp các công cụ và kiểm soát được cải tiến. Một số tiến bộ công nghệ quan trọng hỗ trợ sự phát triển của các hồ dữ liệu bao gồm:
Các lớp siêu dữ liệu để làm việc với các hồ dữ liệu Thiết kế công cụ truy vấn mới cho các tìm kiếm SQL trên các hồ dữ liệu
Về mặt lịch sử, các nhà nghiên cứu đã muốn kết hợp hiệu quả mà kho dữ liệu mang lại với phạm vi rộng lớn của thông tin được hỗ trợ bởi các hồ dữ liệu. Việc hợp nhất các kho dữ liệu với các hồ dữ liệu, để tạo ra một Lakehouse, dẫn đến một hệ thống duy nhất cho phép các nhà nghiên cứu di chuyển nhanh hơn và hiệu quả hơn mà không cần phải truy cập vào nhiều hệ thống.
Các kho dữ liệu hỗ trợ cả hệ thống SQL và dữ liệu phi cấu trúc, đồng thời có khả năng làm việc với các công cụ thông minh kinh doanh. Các doanh nghiệp hiện đại nhận thấy các ứng dụng dữ liệu đa dạng, bao gồm giám sát thời gian thực, phân tích SQL và học máy, khá hữu ích.
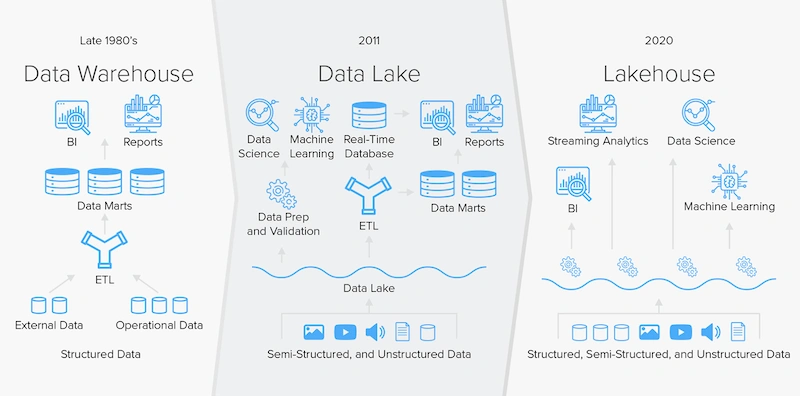
Kho dữ liệu được phát triển vào cuối những năm 1980 và là một nơi tuyệt vời để lưu trữ “dữ liệu có cấu trúc”. Chúng là cơ sở dữ liệu quan hệ được thiết kế cho các truy vấn và phân tích, và thường chứa dữ liệu lịch sử đã được lấy từ dữ liệu giao dịch. Mặt khác, hồ dữ liệu là không gian lưu trữ tổng hợp, tập trung, không tương quan cho dữ liệu thô, chẳng hạn như dữ liệu có cấu trúc, bán cấu trúc và phi cấu trúc.
Các hồ dữ liệu không cần một lược đồ xác định trước, nhưng do đó, các phản hồi truy vấn của chúng không đáng tin cậy và chúng không hỗ trợ ACID. Các hồ dữ liệu được phát triển vào khoảng năm 2015, để lưu dữ liệu có thể có giá trị. Các hồ dữ liệu nhanh chóng trở nên phổ biến cho nghiên cứu dữ liệu lớn.
Việc sử dụng ban đầu của thuật ngữ “data lakehouse” là do một doanh nghiệp có tên là Jellyvision (một khách hàng của Snowflake). Snowflake đã chọn cái tên này và quảng bá nó vào năm 2017, mô tả những nỗ lực của họ trong việc kết hợp xử lý dữ liệu có cấu trúc với hệ thống schemaless.
AWS sau đó bắt đầu sử dụng thuật ngữ này để mô tả các dịch vụ phân tích và dữ liệu “kiến trúc nhà hồ” của mình. Một trong những điểm mạnh chính của data lakehouse được gọi là lớp giao dịch có cấu trúc, được phát triển bởi Databricks vào năm 2019.
Những nỗ lực ban đầu để phát triển các kho dữ liệu còn vụng về, hạn chế và không gây ấn tượng mạnh. Đây là lý do tại sao một số nhà nghiên cứu bày tỏ quan điểm thấp về khái niệm này, và đặt câu hỏi về giá trị của những ngôi nhà ven hồ. (Cần lưu ý, những nỗ lực / thử nghiệm ban đầu thường vấp phải sự chỉ trích và phản đối, nhưng các mô hình đáng giá thường sẽ cải thiện theo thời gian và nỗ lực.)
Vấn đề về Data Lakehouse
Hiện tại, có những tình huống khi các căn nhà ven hồ đơn giản là không hiệu quả bằng các kho dữ liệu, vốn đã có nhiều năm đầu tư, cũng như triển khai trong thế giới thực, được tích hợp vào chúng. Ngoài ra, các nhà nghiên cứu có thể thích một số công cụ nhất định (IDE, công cụ thông minh kinh doanh), những công cụ này sẽ cần được tích hợp vào một kho dữ liệu mới. Những ngôi nhà hồ vẫn đang trong giai đoạn đầu của quá trình tiến hóa, và đây là hai vấn đề cơ bản mà chúng gặp phải:
Công nghệ vẫn chưa phát triển: Các phiên bản hoàn thiện hơn của các căn hộ ven hồ sẽ bao gồm một lượng đáng kể máy học.
Cấu trúc nguyên khối: Các hồ dữ liệu kiểm soát các hồ dữ liệu và kho dữ liệu được hợp nhất, tạo thành các cấu trúc nguyên khối, đồ sộ. Những ngôi nhà ven hồ quá khổ này có thể trở nên không linh hoạt và khó làm việc.
Người đồng sáng lập và CTO của Immuta, Steve Touw, mô tả về nền tảng Lakehouse của họ, cho biết:
“Khi các tổ chức trên toàn thế giới ngày càng nắm lấy các kiến trúc Lakehouse trên đám mây, họ đang phải đối phó với các chính sách kiểm soát truy cập không nhất quán để bảo mật dữ liệu và quyền riêng tư trên các công nghệ khác nhau. Đối mặt với những thách thức mới này, cần thiết phải cung cấp khả năng kiểm soát truy cập dữ liệu đám mây nhất quán và ổn định. Bản phát hành mới nhất của chúng tôi cung cấp cho các nhóm kỹ thuật và vận hành dữ liệu một nền tảng kiểm soát truy cập chung, duy nhất để đơn giản hóa và mở rộng quy mô truy cập phân tích mà không ảnh hưởng đến bảo mật hoặc kiểm soát quyền riêng tư. ”
Lợi ích của Data Lakehouse
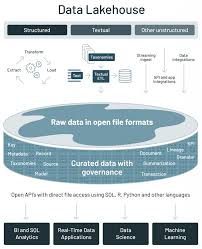
Đạt được thông tin kinh doanh bằng cách xử lý dữ liệu phi cấu trúc, bao gồm video, âm thanh, văn bản và hình ảnh, đã trở thành một nhu cầu cần thiết đối với các doanh nghiệp. Vì kho dữ liệu không được thiết kế cho dữ liệu phi cấu trúc, một số tổ chức đã chọn quản lý đồng thời nhiều hệ thống (một số kho dữ liệu, một hồ dữ liệu, các hệ thống chuyên biệt khác).
Mặc dù chiến thuật này giải quyết được một số vấn đề, nhưng nó rất vụng về, không hiệu quả và lãng phí tiền bạc. Ngoài ra, việc duy trì nhiều hệ thống khác nhau có thể làm chậm nỗ lực đạt được thông tin kinh doanh hữu ích và kịp thời.
Data lakehouse được thiết kế để điều hòa dữ liệu có cấu trúc, được lưu trữ trong các cột và hàng, với dữ liệu phi cấu trúc thường được đưa vào các hồ dữ liệu. Ori Rafael, Giám đốc điều hành của Upsolver, đồng thời là người đồng sáng lập, cho biết:
“Với một ngôi nhà hồ, bạn đang có được lợi thế về chi phí của một hồ dữ liệu, nhưng bạn đang quản lý để sử dụng các công cụ bạn đang sử dụng hiện nay, giúp bạn dễ dàng truy cập. Lakehouse là hồ dữ liệu không có tất cả các giới hạn và khó khăn để truy cập dữ liệu. ”
Nói chung, một data lakehouse duy nhất có một số lợi thế so với một hệ thống nhiều giải pháp, bao gồm:
Các công cụ có quyền truy cập trực tiếp vào dữ liệu cho mục đích phân tích Quản lý trở nên dễ dàng và hiệu quả hơn Ít nhầm lẫn hơn về lược đồ và Quản trị dữ liệu Không tốn nhiều thời gian để di chuyển dữ liệu xung quanh phát trực tuyến từ đầu đến cuối. Được sử dụng để tinh chỉnh, truy cập và phân tích các loại dữ liệu, bao gồm video, âm thanh, hình ảnh và văn bản.
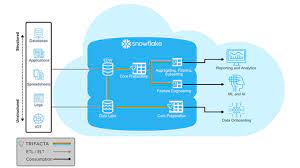
Bông tuyết
Snowflake là một nền tảng Lakehouse linh hoạt cho phép sử dụng các công cụ thông minh kinh doanh truyền thống và cũng hỗ trợ các công nghệ mới hơn, tiên tiến hơn, chẳng hạn như trí tuệ nhân tạo, máy học và khoa học dữ liệu. Nền tảng này kết hợp các kho dữ liệu, hồ dữ liệu và kho dữ liệu theo chủ đề cụ thể để cung cấp thông tin chính xác, do đó, có thể hỗ trợ nhiều dự án khác nhau. Snowflake Lakehouse là một nền tảng tích hợp có khả năng thực hiện nhiều chức năng, bao gồm:
Phát triển ứng dụngTruy cập dữ liệu nhanhPhân tíchKỹ thuật dữ liệuTạo mô hình AI và học máy
Databricks
Nền tảng Databricks Lakehouse cung cấp Quản lý dữ liệu và hiệu suất thường được cung cấp bởi các kho dữ liệu, nhưng với chi phí thấp của các hồ dữ liệu. Nền tảng hợp nhất của họ đơn giản hóa kiến trúc bằng cách loại bỏ các silo dữ liệu và họ đã phát triển lớp giao dịch có cấu trúc vào năm 2019, cung cấp khả năng quản trị, chất lượng, cấu trúc và hiệu suất. Lakehouse của họ hỗ trợ:
Kỹ thuật dữ liệu Trí thông minh kinh doanh và phân tích SQL
Amazon Redshift
Nền tảng Amazon Redshift lakehouse hỗ trợ nghiên cứu trên các kho dữ liệu, hồ dữ liệu và cơ sở dữ liệu hoạt động. Với kiến trúc này, dữ liệu có thể được lưu trữ ở các định dạng tệp mở trong hồ dữ liệu Amazon S3. Sự sắp xếp này giúp dữ liệu dễ dàng truy cập vào các công cụ phân tích và học máy, thay vì chuyển nó vào một silo. Kiến trúc ngôi nhà trên hồ Amazon Redshift hỗ trợ:
Truy vấn hồ dữ liệu dễ dàng sử dụng định dạng mở Các câu lệnh SQL quen thuộc có thể kết hợp và xử lý dữ liệu được lấy từ tất cả các kho dữ liệu Thực hiện tìm kiếm trên dữ liệu trực tiếp trong cơ sở dữ liệu hoạt động mà không cần tải dữ liệu và đường ống ETL
Tương lai của Data Lakehouse
Kiến trúc data lakehouse cung cấp khả năng quản lý dữ liệu trong môi trường mở, đồng thời kết hợp nhiều định dạng dữ liệu từ tất cả các bộ phận của doanh nghiệp. Mặc dù các bài đánh giá về phiên bản đầu tiên của nó có thể khiến bạn nghi ngờ về hiệu quả của nó, nhưng nó dường như đang trở nên phổ biến như một cách hiệu quả hơn để lưu trữ và xử lý khối lượng lớn dữ liệu không cấu trúc, có cấu trúc và bán cấu trúc. Có những lợi thế rõ ràng về hiệu suất và hiệu quả trong việc sử dụng các kho dữ liệu và có thể dự đoán được, chúng sẽ tiếp tục phát triển khi hệ thống tiến bộ và các ứng dụng và công cụ mới được phát triển.
Juan Harrington tại Omnitech gần đây đã viết:
“Lakehouse là một cách tiếp cận kiến trúc mới để giải quyết một số vấn đề ngày nay về phân tích và học máy ở quy mô lớn. Mặc dù vẫn còn trong giai đoạn sơ khai, nhưng Lakehouse sẽ tiếp tục phát triển và trưởng thành. ”
Từ khóa:
- databricks lakehouse
- Building the data lakehouse pdf
- primary services that comprise the databricks lakehouse platform
- access point to the databricks lakehouse platform for data engineers
- Data Lakehouse là gì
- databricks lakehouse primary services
- databricks lakehouse architecture
Nội dung liên quan:
- Tối ưu hóa thực tế ảo (VEO): Sự phát triển tiếp theo của SEO?
- Nền tảng này vừa trở thành trang web phổ biến nhất
- Top 7 xu hướng marketing sẽ quan trọng nhất trong năm nay
