
Cụm từ “khoa học dữ liệu là gì” được sử dụng hàng ngày, kể cả trong chính ấn phẩm này. Chúng tôi cảm thấy như chúng tôi có một ý tưởng nó là gì. Nhưng chính xác là nó? Để có một câu trả lời, chúng tôi chuyển sang Jeffrey Ullman, người đã giành được Giải thưởng Turing vào năm 2022. “Khoa học dữ liệu đến từ đâu?” đã hỏi Ullman, một giáo sư khoa học máy tính của Đại học Stanford, trong bài phát biểu quan trọng của mình tại hội nghị Nhóm lợi ích đặc biệt ACM lần thứ 27 về Khám phá và Khai thác Dữ liệu.
“Vào khoảng đầu thiên niên kỷ, mọi người đã nói về khai thác dữ liệu hoặc khám phá kiến thức, từ đó SIGKDD lấy tên của nó,” ông tiếp tục. “Sau đó vào khoảng năm 2010, bạn không thể nói rằng mình đang làm điều đó nữa. Bạn phải nói rằng bạn đang làm dữ liệu lớn. Và bây giờ bạn cần phải nói rằng bạn đang làm khoa học dữ liệu. Nhưng khái niệm đằng sau những từ thay đổi này đã không thực sự thay đổi. ”
Vì vậy, khoa học dữ liệu là gì?
Khoa học dữ liệu là gì? Theo lời kể của Ullman, khoa học dữ liệu, như nó được hiểu một cách phổ biến, bao gồm một loạt các lĩnh vực, bao gồm thống kê, toán học, học máy, trí tuệ nhân tạo, khai thác dữ liệu, khám phá kiến thức, trải nghiệm miền và tất nhiên, khoa học máy tính và nghiên cứu hệ thống cơ sở dữ liệu, đó là lĩnh vực chuyên môn của Ullman.
Nhưng những yếu tố nào là cần thiết, và với số lượng bao nhiêu, để một người tuyên bố làm “khoa học dữ liệu”, hay cho một người tuyên bố là “nhà khoa học dữ liệu” cho vấn đề đó? Có một số cuộc tranh luận về các yếu tố và tỷ lệ thích hợp, thường được truyền đạt thông qua phương tiện đồ họa được gọi là biểu đồ Venn.
“Hóa ra mọi lĩnh vực đều có định nghĩa riêng về khoa học dữ liệu,” Ullman nói, “và đó là định nghĩa giúp nâng cao tầm quan trọng của lĩnh vực đó và nó có thể được biểu thị bằng biểu đồ Venn.”
Giáo sư Khoa học Máy tính của Đại học Stanford, Jeffrey Ullman, trong bài thuyết trình KDD2021 của mình hôm thứ Hai, là người đồng chiến thắng Giải thưởng Turing năm 2020
Trước khi chia sẻ biểu đồ Venn của riêng mình về các yếu tố cần thiết trong khoa học dữ liệu, Ullman đã đưa một trong số chúng vào nhiệm vụ, cụ thể là biểu đồ Venn về khoa học dữ liệu phổ biến do Drew Conway tạo ra (bạn có thể xem ở đầu bài viết này). Có thể bạn đã thấy biểu đồ Venn của Conway, với ba vòng tròn chồng lên nhau thể hiện kỹ năng hack, kiến thức toán học và thống kê cũng như kiến thức chuyên môn đáng kể (đó là kết quả đầu tiên khi bạn Google “biểu đồ Venn khoa học dữ liệu”.
Ullman nói: “Khoa học dữ liệu là gì? Lý do tôi tập trung vào điều này là vì tôi đã nhiều lần nghe các nhà thống kê trình bày sơ đồ này như là định nghĩa thực sự của khoa học dữ liệu. “Có gì sai với nó? Chà, hóa ra mọi thứ đều không ổn với nó ”.
Ullman đã liệt kê một số ý kiến phản đối, bắt đầu bằng việc Conway sử dụng thuật ngữ “chuyên môn sâu sắc”. Ưu tiên của Ullman là kiến thức về miền. Nhưng đây chỉ là một sự ngụy biện đơn thuần, vì Ullman chỉ mới bắt đầu.
“Đây là điều thực sự khiến tôi phát điên,” anh tiếp tục. “Khoa học máy tính không chỉ là viết mã. Chúng tôi có rất nhiều mô hình, mô hình trừu tượng, thuật toán – tất cả đều làm cho giải pháp của các vấn đề khoa học dữ liệu trở nên khả thi. Một chút tôn trọng sẽ có được trong trật tự. ”
Ullman cũng phản đối khu vực giao nhau giữa “kỹ năng hack” và “chuyên môn sâu”, mà Conway gọi là “khu vực nguy hiểm”.
“Conway gọi một nhà khoa học máy tính đang cố gắng giúp một nhà khoa học miền nào đó là mối nguy hiểm, nếu họ không hoạt động dưới sự hướng dẫn khôn ngoan của một nhà thống kê,” Ullman nói. “Tôi sẽ tranh luận rằng hầu hết các thành tựu của khoa học dữ liệu thực sự thuộc loại này, với phần này của biểu đồ Venn.
Mặc dù người ta có ấn tượng rõ ràng rằng Ullman không quá ấn tượng với các nhà thống kê (hoặc ít nhất là cách họ nhìn nhận tầm quan trọng của họ đối với lĩnh vực khoa học dữ liệu), ông cũng không muốn bác bỏ họ hoàn toàn.
Ông nói: “Thành tựu của họ đã đạt được rất nhiều, và các công cụ mà họ tạo ra có những công dụng quan trọng trong khoa học dữ liệu và khoa học máy tính nói chung. “Nhiều nhà thống kê bắt đầu quan tâm đến các vấn đề khoa học máy tính và có thể đóng góp quan trọng.”
Đánh dấu của Giáo sư Ullman về sơ đồ Venn Khoa học dữ liệu là gì?
Ví dụ, Ullman đã ghi công một trong những đồng nghiệp Stanford của mình, một nhà thống kê, đã giới thiệu cho anh ta một kỹ thuật giảm dữ liệu mạnh mẽ được gọi là băm nhạy cảm theo địa phương. “Khoa học dữ liệu là gì? Anh ấy đã có thể chỉ cho tôi một thứ giúp tăng tốc một trong những thuật toán quan trọng trong lĩnh vực đó được gọi là min-băm, lên rất nhiều,” Ullman nói. “Đáng lẽ tôi đã có thể nhìn thấy nó trước khi chính mình. Nhưng tôi thì không. Anh ta đã làm.”
Ullman cũng chỉ trích sự giao thoa giữa kiến thức toán học và thống kê và kiến thức chuyên môn sâu trong biểu đồ Venn của Conways. “Đây là những gì Conway gọi là nghiên cứu truyền thống. Cung cấp số liệu thống kê cho một vấn đề mà không cần viết bất kỳ mã nào, ”Ullman nói. “Tôi không biết đó là truyền thống của ai, nhưng tôi hy vọng đó không phải là của bạn. Tất cả những gì làm được chỉ mang lại sự giải trí cho các nhà thống kê hoặc nhà toán học, và nó không cung cấp giải pháp cho bất kỳ điều gì ”.
Ditto cho máy học như là giao điểm của hack và toán học / thống kê. “Học máy có thực sự là thứ không áp dụng cho bất kỳ miền nào không?” Ullman hỏi. “Chà, đã có một số thành tựu tuyệt vời khi mọi người nhìn vào phương pháp luận trong học máy hơn là áp dụng nó. Tôi nghĩ rằng lý do mà mọi người muốn tham gia vào học máy ngày nay là vì nó rất hữu ích trong việc giải quyết các vấn đề trong nhiều lĩnh vực khác nhau. ”

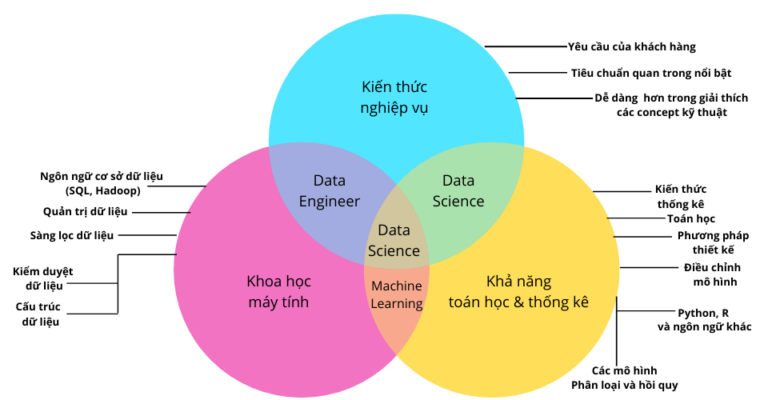
Sau khi phổ biến sơ đồ Venn của Conway, Ullman đã cung cấp sơ đồ của riêng mình.
Ông nói: Khoa học dữ liệu là gì? “Có khoa học máy tính và có những lĩnh vực khoa học mà chúng tôi muốn chúng tác động đến và ở đâu đó ở giữa là khoa học dữ liệu. “Giờ đây, học máy là một nhánh của khoa học dữ liệu. Nó được sử dụng cho rất nhiều công việc khuấy động các lĩnh vực ứng dụng, nhưng nó cũng được sử dụng trong các vấn đề nội bộ thuần túy của khoa học máy tính, thường là trong các ứng dụng được gọi là trí tuệ nhân tạo, thay vì máy học. ”
Ví dụ, học máy rất hữu ích trong việc phát hiện sự xâm nhập vào hệ thống máy tính, mà Ullman nói là một chủ đề thuộc về khoa học máy tính chứ không phải trong bất kỳ lĩnh vực ứng dụng cụ thể nào. Học máy cũng hữu ích trong việc tạo ra những thứ chung chung như bot trò chuyện, cũng không thuộc bất kỳ miền cụ thể nào, ông nói.
“Bây giờ, toán học và thống kê đều có vai trò trong bức tranh này,” Ullman nói, trong khi xin lỗi về kích thước của bong bóng của mình. “Nhưng quan điểm của tôi là toán học và số liệu thống kê có rất nhiều ứng dụng trong khoa học máy tính. Nhưng chúng không tự ảnh hưởng đến các miền. Họ làm như vậy thông qua các thuật toán mà họ giúp thiết kế và phân tích. ”
Trong một số trường hợp, toán học và thống kê rất quan trọng để chứng minh rằng các thuật toán được phát triển bằng khoa học máy tính và kỹ năng học máy hoạt động, mặc dù chúng không thực sự được sử dụng trong quá trình phát triển của chính thuật toán. Và không phải tất cả các vấn đề về dữ liệu lớn đều yêu cầu các mô hình học máy hoạt động, Ullman nói.
Sơ đồ Venn Khoa học dữ liệu của Profssor Ullman
Ví dụ Khoa học dữ liệu là gì?: kỹ thuật băm phân biệt địa phương (LSH) đã đề cập trước đây và thuật toán Flajolet-Martin, được sử dụng để đếm gần đúng, không phải là thuật toán học máy, nhưng chúng rất hữu ích để giải quyết các vấn đề dữ liệu lớn.
Cũng có những tuyên bố đòi hỏi sự chính xác trong tính toán thống kê. “Ví dụ: khi bạn tuyên bố 10% dân số nghèo ở một nơi nào đó, có phải bạn muốn nói rằng có 95% xác suất rằng tỷ lệ phần trăm thực tế là từ 9 đến 11%? Hoặc xác suất 75% nằm trong khoảng từ 2% đến 20%? ” Ullman nói. “Bạn cần hiểu đúng câu chuyện.”
Tuy nhiên, có những hạn chế với khả năng áp dụng của phương pháp thống kê. Ví dụ, Ullman đã thảo luận về một cuộc thi hackathon gần đây, trong đó những người tham gia dành một ngày cuối tuần để tìm kiếm “điều gì đó thú vị” ẩn trong dữ liệu.
“Tôi đoán điều đó có thể rất thú vị như một cuộc thi,” Ullman nói. “Nhưng sẽ không tốt hơn nếu khuyến khích học sinh lấy cùng dữ liệu đó và sử dụng nó để giải quyết vấn đề mà ai đó quan tâm? Vì vậy, đối với sở thích của riêng tôi, tôi thích cách tiếp cận Kaggle hơn, nơi những người thực sự muốn có giải pháp cho một vấn đề có thể đăng các tập dữ liệu và mọi người cạnh tranh để giải quyết vấn đề để giành giải thưởng tiền mặt. ”

Những người có xu hướng giải thích thống kê của khoa học dữ liệu dường như quên khía cạnh thực nghiệm của đồng xu, ông nói. Ông nói: “…. Khoa học dữ liệu là gì? “Nếu bạn muốn biết liệu ý tưởng của mình có giải quyết được vấn đề bạn đang làm hay không, thì hãy triển khai, chạy nó và xem.”
Chủ nghĩa kinh nghiệm thực tế của khoa học dữ liệu được hiển thị hàng ngày thông qua các cơ chế chống spam của Google. Ullman nói rằng sự giao thoa giữa hack máy tính và chuyên môn về miền sẽ nằm trong vùng nguy hiểm của Conway. Ông nói: “Hãy nghĩ về những gì sẽ mất đi khi vứt bỏ phần mềm. “Mọi người sẽ rơi vào bẫy của những kẻ gửi thư rác trên khắp thế giới.”
Từ khóa:
- Khoa học dữ liệu ra làm gì
- Mức lương ngành khoa học dữ liệu
- Khoa học dữ liệu trường nào
- Tương lai của ngành Khoa học dữ liệu
- Con gái có nên học khoa học dữ liệu
- Khoa học máy tính và khoa học dữ liệu
- Khoa học dữ liệu UEH
- Review ngành Khoa học dữ liệu
Nội dung liên quan:
- 4 ngành trong đó dữ liệu tổng hợp đã làm tăng tác động của AI
- 8 phụ nữ truyền cảm hứng cho những tiến bộ hàng đầu trong lĩnh vực AI
- 4 Mẹo công nghệ cải thiện cuộc sống của bạn
